Papers
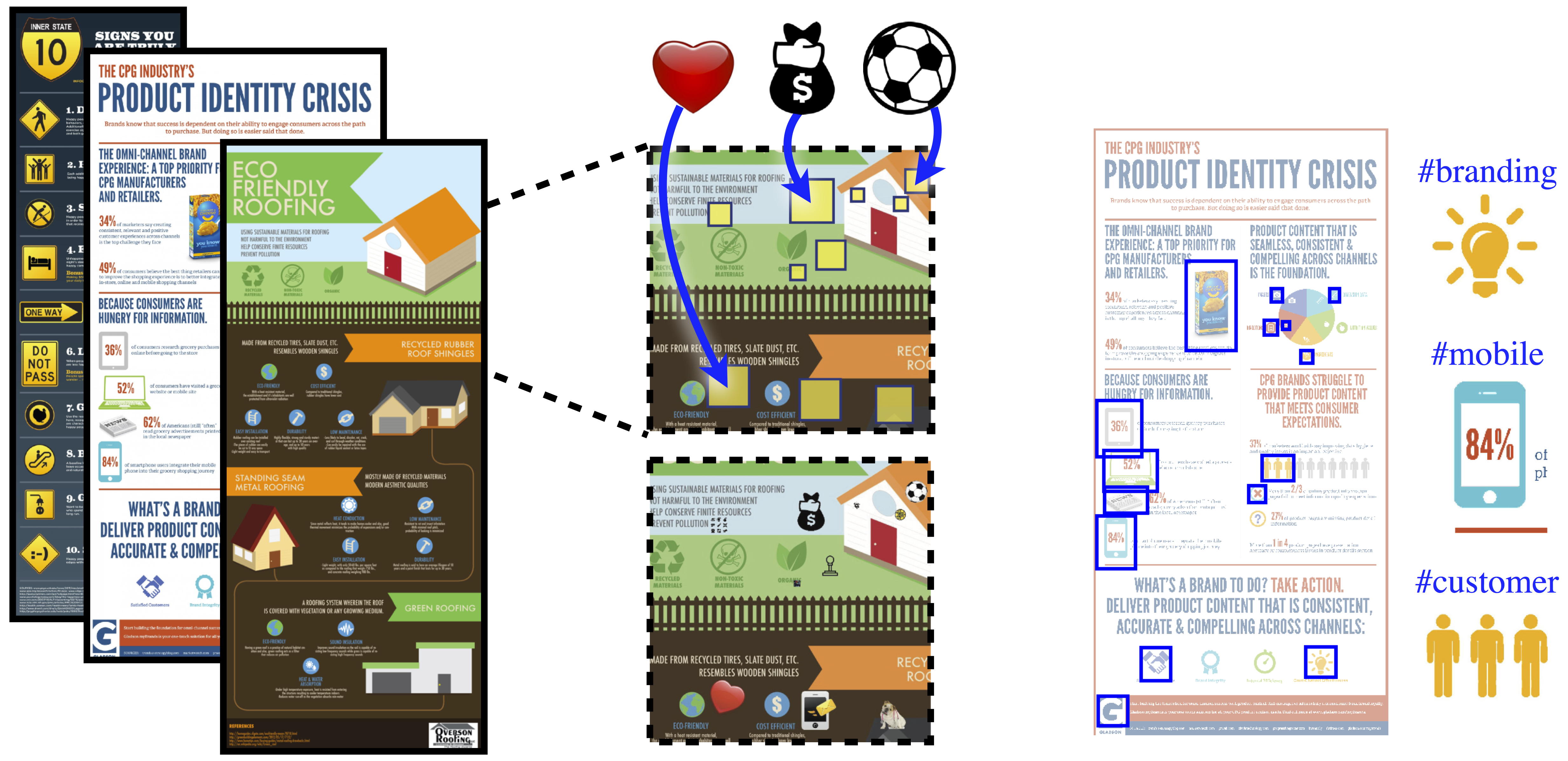
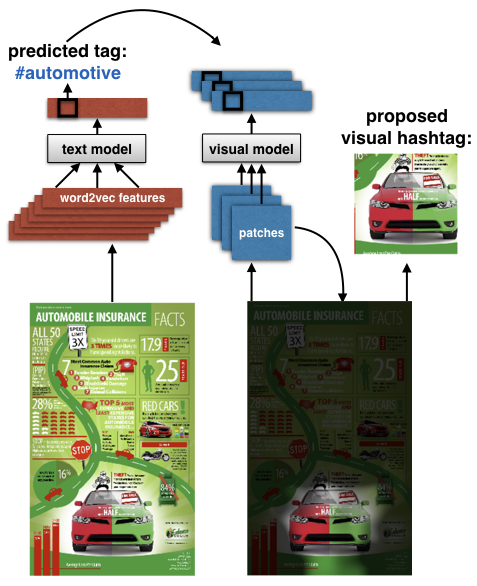
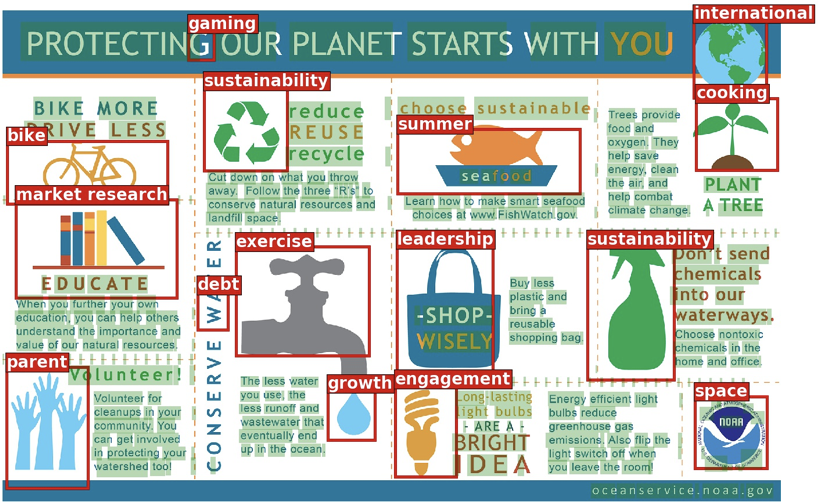
"Synthetically Trained Icon Proposals for Parsing and Summarizing Infographics" uses this dataset to train an icon proposal mechanism (icon detection for infographics), and demonstrates an automatic summarization application. "Understanding Infographics through Textual and Visual Tag Prediction" was an earlier paper demonstrating results on the task of tag prediction, by extracting the text and visual content from within an infographic.